It appears Latent events aren’t working properly, they trigger correctly but sometimes trigger multiple times.
This happens whenever the bits per second is higher than the amount of bits transmitted (or when there’s bits leftover in buffer after all data is read , has something to do with the buffer probably)
IE: you sent something containing 2 bytes like “hi” through a latent event with 2000000 bps it will trigger 1000000 times (give or take, haven’t looked into the exact numbers)
I’ve included a small test resource to illustrate the issue, it builds a string containg 1000 entries of test and sends it with 1000000 bps, it results in the client event running aprox. 214 times. It also includes the log illustrating the resulting debug print at the end of the file latenteventbug.zip (72.7 KB)
WARNING
If you post here without knowing what you’re doing you’ll most likely get suspended, you should probably post in #technical-support instead.
This is likely related to there being no timer on resending… not sure if that’d be a proper fix but at least having a repro should show if it does help.
I will test this a bit in my development environment, and when this hits recommended I will start using some latent events again and see if it’s fixed.
Much appreciated anyway since this can save quite a bit of bandwidth spikes.
This is still happening on Canary + 3961 but way less
These settings are better for a repro (at least for me)
RegisterCommand(‘testlatentserver’, function(source, args, raw)
print(“Triggering server to client event…”)
local sb = {}
for i=1, 5000 do
sb[#sb+1] = ‘test’
end
TriggerLatentClientEvent(‘testlatentclient’, -1, 1000000, table.concat(sb))
end)
In instances of the client ‘receiving’ the same event twice, packetIdx is looping around with targetData->lastBit == startBit evaluating to false.
With manzareks example, the payload is broken down into twenty fragments and in one tick EventPackets are sent for [19, 0, 1, 2, ..., 7] while startBit is 9.
A quick-and-dirty remedy would be to change the equality operator, e.g., if (targetData->lastBit <= startBit), the first time iterating over the fragments (or possibly every time?). If this fixes the problem, delayNextSend should probably be tested/tuned by somebody with a large enough server (and brave enough to use the feature). Ensuring it holds up to the rigours of peoples misuses of networking natives and whatnot.
I’ll get around to testing this sooner or later, I will include Sentry logging when I get around to it (waiting for next recommended release)
Got around 450 players on simultanously so that should be enought to test it.
Really hate the bandwidth spikes, so been anxious to get around to using this anyways.
What bit rate settings are you using?
When I enabled them after last fixes I couldn’t replicate issues but some client had the events not triggering properly.
I saw also that txadmin disabled a latent event recently maybe they hit some issue too?
I know this is another useless message stating a bug without repro that need ‘a lot of players’.
If you could share your settings I could give latent events another try
I asked them to diagnose the issue that only 2-3 people had, but instead of following the steps I asked for they just did nothing and apparently went ‘back’ to this nonsense. I suspect it’s some MTU issue though for some connections, hard to tell without being a person who is actually affected by events not arriving however - this time player count is not relevant though, these affected users had this issue even with the server nearly empty.
As of now I’m noticing some latent events sometimes triggering multiple times, but this changes when I change the bytes per second.
Seems to me like it’s something to do with packet loss, but I’ll keep an eye out on some tcpdumps and wireshark to see if it actually gets sent multiple times.
So far I haven’t heard anybody about event not being triggered at all (this would also cause a timeout as far as I’m aware so seems like a scripting issue if that would happen)
I now added latent event in some chat related events, so people can check that back in Discord, so this way it’s easy to track the issue and I’ll see what affects the issue.
As for values I’m using, basically anything within 12500 - 100000 bytes per second works fine. Haven’t tried higher yet as it’s a server with 600 players so I like to keep the bandwidth as low as possible.
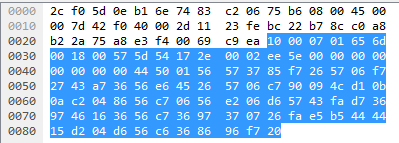
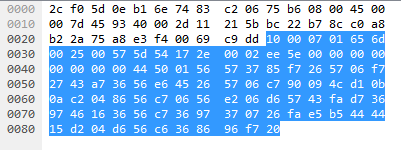
What I can see here is that the ACK’s aren’t being sent, so the two packets of length 97 towards the end are sent twice, with 0.3 seconds inbetween them, and only after the second one an ACK is sent.
First packet:
Second packet:
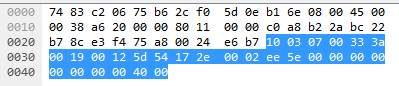
ACK packet:
The only difference between the two packets is byte 31, which changes from 18 to 25.
Can still somehow try to increase chances of such occurring.
I’m not sure what @gottfriedleibniz ‘noted’ earlier or where this was noted, it’s hard to track information if there’s 6-7 different places it can be posted.
I’m gonna guess this was what gottfried was referring to.
Also to add to this, I just inspected another one of these occurences, and the ACK does appear to be sent out. But packet into another packet (a msgPackedClones) which is as expected.
But the being packed into another packet might be a thing? Since that also happened with the other event which got triggered twice.
I’ll try to get a dump on the server side to to verify that the ACK is being received to eliminate packet loss on the ACK as a cause.
Edit:
Just checked it using a dump on all sides, it does appear that the packets being packet together is what causes it in some way.
The msgReassembledEvent containing the ACK’s is being received on the server, but packed into another msgRoute packet (depends on the case, can be any unreliable packet) and then later on the server just sends the packet again even though the ACK was received.
So I can see both packets on my own computer and on the server (using tcpdump and wireshark) the event is received twice, and the ACK’s are also sent twice. Whether or not this occurs is also not global, so the same event is sent to everyone, but not everyone has a duplicate, which makes me point the finger to packet loss, which I have confirmed is not the cause, or as stated, the ACK’s being packed into another packet.
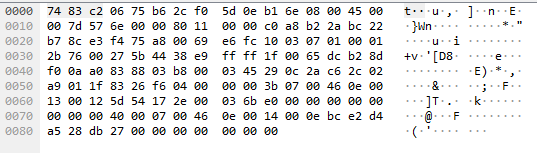
The packet where the ACK’s are packed with another unreliable event:
While this should* not lead to issues, it is still very leaky as that data will reside in m_receiveList until UnregisterTarget is invoked when the client disconnects.
* - Although, if the event fits into one packet (or a small number of packets in an incredibly noisy environment?), hasAll could be true after the second m_receiveList: Inserting eventId instance (Clumsy could probably verify this). Besides that one possibility, I don’t see any other client/server ping-pong effect that would emerge from this.