We have been having issues recently with the our FiveM server dropping all connected clients. It is happening every 3-6 hours during peak time, and causes all the players to suddenly drop from the server.
Description of Issue
Just before everyone disconnects, the players can still see each other moving around, and can interact with each other, however net events stop working at all. In the server console, there is a large “network thread hitch warning” spam, usually with each hitch being < 500ms.
After everyone drops, the server is unrecoverable. People can still join, however never make it off the load screen. They drop shortly after the finish loading (according to F8 console), and a server restart is needed to allow people to connect again.
During this time, I set the server capacity to 5 slots. I was able to connect (for no more than a few minutes). It would seem that broadcast events worked flawlessly (Client events which target -1) however events directed to a specific player only worked sporadically.
Once the player is unable to receive directed net events, they disconnect shortly after.
Server Details
Currently running on v3961. At one point I had a modified scheduler.lua to log network events sent by the server. We used this to try and find problematic patterns however have not had much luck yet. Crashes occur without the modified file as well.
ETW Trace
Here is a few ETW traces when the server is in the broken state, 1 is trace to file, and the other is circular trace buffers (not sure which is useful)
etwtraces.zip (76.4 MB)
Client Error Message
The message the clients get is show below (Just a standard timeout message).
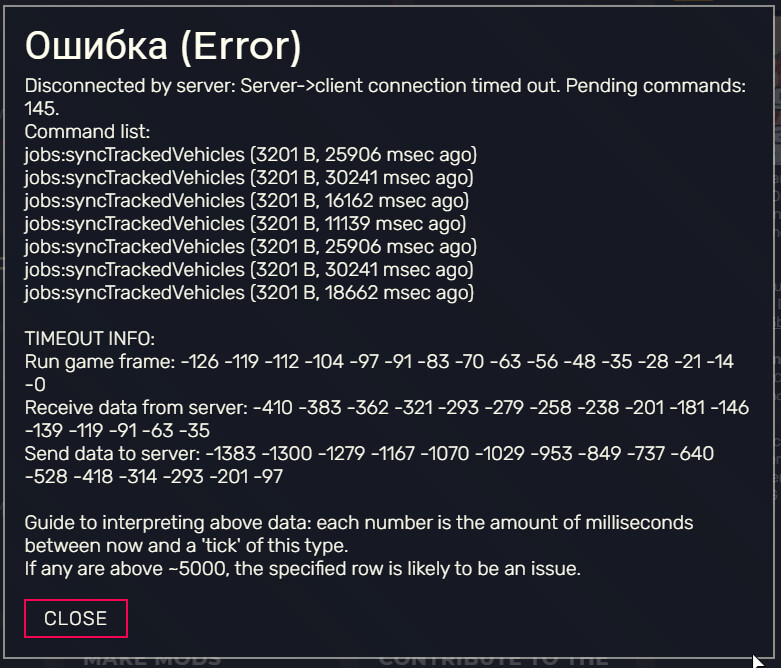
One thing of note is the “syncTrackedVehicles” which is a net event which fires fairly frequently, about every 2.5 seconds. However, this used to be other net events, which we removed to test if it would improve. It seems to just appear in the list because they are frequent, but potentially not the cause.
I’ll keep updating this post with more information as I discover it, even some of the info here might not be super accurate because it is quite challenging to decipher things.
