So i recently (3 days ago) opened a freshly made server and im experiencing some crashes that i really dont understand.
- Latest server build
- Gamebuild 2612
Initially all i could see was
[ citizen-server-impl] network thread hitch warning: timer interval of 783 milliseconds
[ citizen-server-impl] sync thread hitch warning: timer interval of 797 milliseconds
> txaEvent "serverShuttingDown" "{"delay":5000,"author":"txAdmin","message":"Server restarting (crash detected)."}"
Thoses are screenshots of sync, network and main from txAdmin
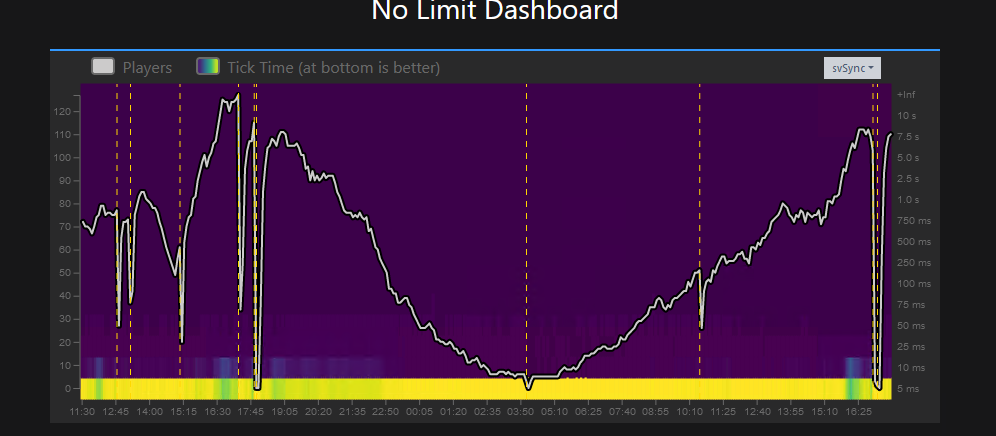
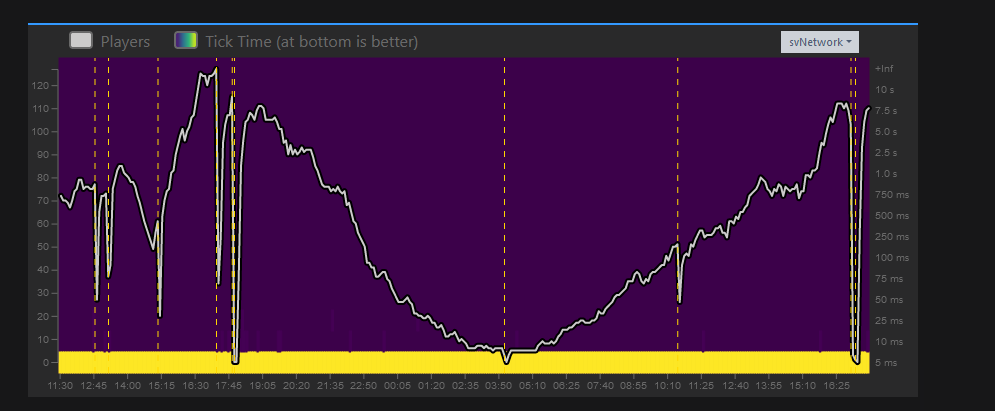
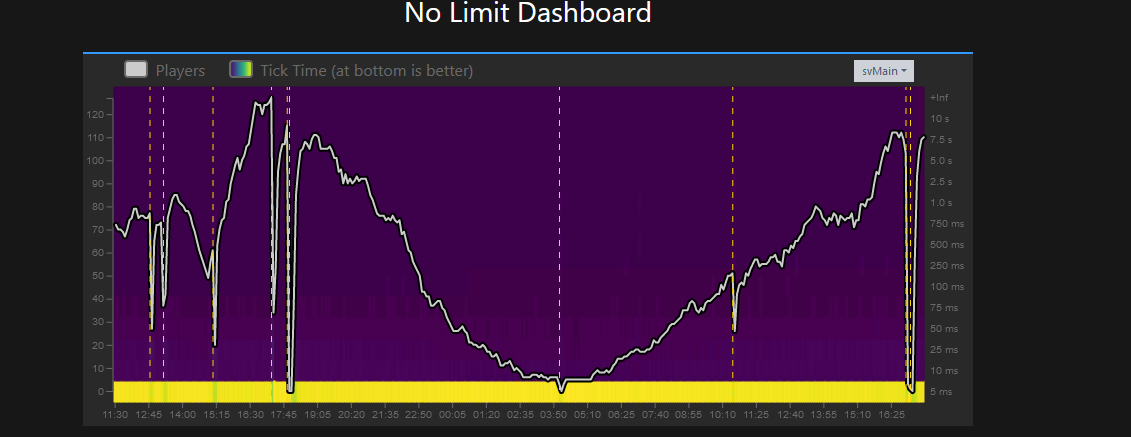
I did not get to run a profiler when the crash happens but here a screenshot of the profiler after 6 hours of uptime and about 70 players
https://cdn.discordapp.com/attachments/945425259958501447/1054484559116386434/image.png
On first day i had no crashes at all but a resource called pefcl was runing on dev branch and keep timing out its mysql connection.
After using a release version wich alot of people are using without any issues theses crashes has start to happen.
Currently running the server on ox_core and most of overextended stuff. around 120 resources on the server.
No hitch warning expect for the 2 in the snipet right before a crash. Wich according to tabbara in txAdmin are very much negligeable.
Running phoenix-ac, tried to turn it off wondering if it was the issue but it dosent look like it is.
While monitoring, right before the last crash i saw this
Got a SIGSEGV while executing native code. This usually indicates
a fatal error in the mono runtime or one of the native libraries
used by your application.
=================================================================
=================================================================
Managed Stacktrace:
=================================================================
=================================================================
[ citizen-server-impl] network thread hitch warning: timer interval of 1086 milliseconds
[ citizen-server-impl] sync thread hitch warning: timer interval of 1085 milliseconds
I only saw that message once.
The more i search the more i get confused as to what the source of these crash would be.
When looking at pretty much everything i can think of the server looks super stable but then 30 minutes later it crashes.
I think an important point would be that i often crashes right after a start.
Server starts
2/3 player logs in and then server crashes.
At this point im just looking for an external opinion or what i should be looking for kind burning my brain over this.
Any help would be very much appreciated really.
