Hello, recently we’ve been trying out various builds on our Linux server - we’ve tried 2744 and 2788 - and we’ve been encountering an issue where FXserver will randomly just close itself with 0 output on either stderr or stdout.
The only indication that anything wrong’s been going on that I’ve found is in /var/log/syslog.
Here is an excerpt of various segfaults:
#running 2744, nothing happened
Jul 30 17:02:14 kernel: ld-musl-x86_64.[26522]: segfault at 7f1097d0e4e0 ip 00007f10c871b289 sp 00007f10b8c20028 error 4 in libcitizen-scripting-mono.so[7f10c85da000+281000]
#running 2744, crashed at the same time
Aug 1 22:07:30 kernel: luv_svMain[24975]: segfault at 7f0800000009 ip 00007f085d4e04ff sp 00007f0851951cd0 error 6 in libnet-http-server.so[7f085d4ce000+67000]
#running 2744, nothing happened
Aug 3 10:46:28 kernel: luv_svMain[2675]: segfault at 79 ip 00007f030926977c sp 00007f02fe3a9c10 error 4 in libcitizen-resources-core.so[7f030924a000+9c000]
#running 2788, crashed at the same time
Aug 4 04:56:13 kernel: luv_svMain[10892]: segfault at 0 ip 0000000000000000 sp 00007f9db55f4198 error 14
It’s crashed a few extra times with nothing in syslog either so I have no idea as to what could be causing this.
If there is any extra information that I can provide somehow just let me know (& how).

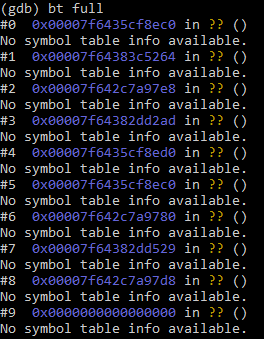
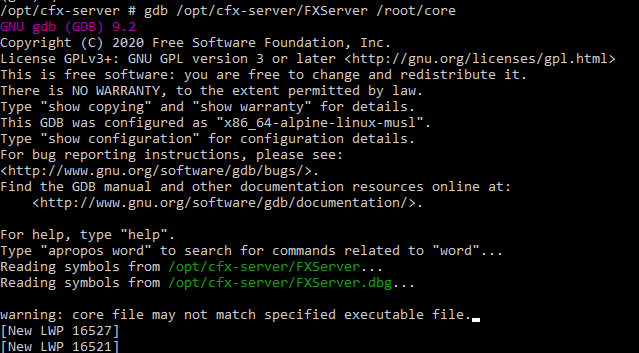

 ? We’re working towards Windows soon, I’m just trying any last leads…
? We’re working towards Windows soon, I’m just trying any last leads…
