Not to be repeating myself…
The server is running without the restart script. Crashed terminally without restarting. The second time this experiment has been run. Twice now FiveM 1347 has crashed without the Starter Script being active.
So what I am seeing, is that the server during a calm period where only heartbeats are registering, after a lengthy hitch session says “Killed” which the first time seems to have meant nothing. The server continues to send heatbeats, but now looks like it is failing to connect, followed by a second hitch session, and a second “Killed” which is the last thing in the log.
putty_1348-2.log (18.2 KB)
1347 not 1348^^ can’t change it 
Which raises the question of linux server logging. If it can say heartbeat, and it can say Killed, why can’t it say a lot more things? If it can’t log, why can’t it create a dump file?
Your dmesg is literally full of the server process (and other processes, such as apache2) getting killed due to being “out of memory”. It seems your server has only 512 MB of RAM, and you’re running multiple intensive server processes? This was a common amount of memory for a PC in 2003, not in 2019. Due to all the background processes going on, the server is getting killed when its memory usage is merely 128 MB, which is a perfectly normal amount of memory to be used by a game server.
Try shutting down stuff like apache2 (which takes around 70% of your server’s memory), exim4, and other things you don’t need, or get more RAM.
Even if this’d be a normal crash (which it isn’t - it’s the OS forcibly terminating the server because you’re running with only 512 MB of memory with random other processes using 70% of it), making a crash dump file on Linux would be completely futile since there’s no software that can open it due to the way Linux works with dynamic linking.
While running FiveM Server and an apache2 stress test, CPU 23%, and 323MB RAM free. Apache2 under test appears to not be occupying more than 20% of ram. I additionally have 512mb of swap which goes unused 24/7 for 3 years.
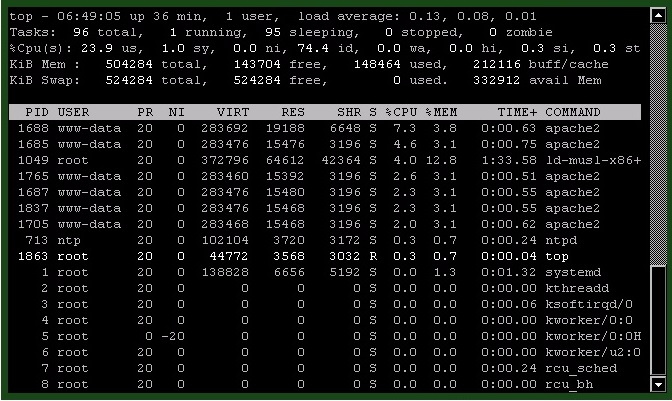
free -m appears to confirm this

The only tasks running on this server is 1 website @ 250 users a day, and 1 usually half full FiveM server. The website operates perfectly, I’ve never once seen a download or page load fail. FiveM until 1317 ran perfectly. I never once saw it crash. The VPS is largely unchanged for three years.
Presumably, your server is configured to just kill processes before using it. Linux memory management is a weird one, it’ll OOM kill long before it indicates anything as being wrong.
Of interest is that 1347 seems to fail following the hitch warning sessions. I have an identically prepared VPS that I dev FiveM on, that is currently idling the same setup, on 1244, waiting for FiveM to stop blocking the masterlisting of it. And in its log i see the same behavior of the FiveM server/package a large hitch session, perhaps of my own causing. But unlike post-1317 it does not crash as a result of this hitch session, which is currently occurring with no players on the server, none ever joined:
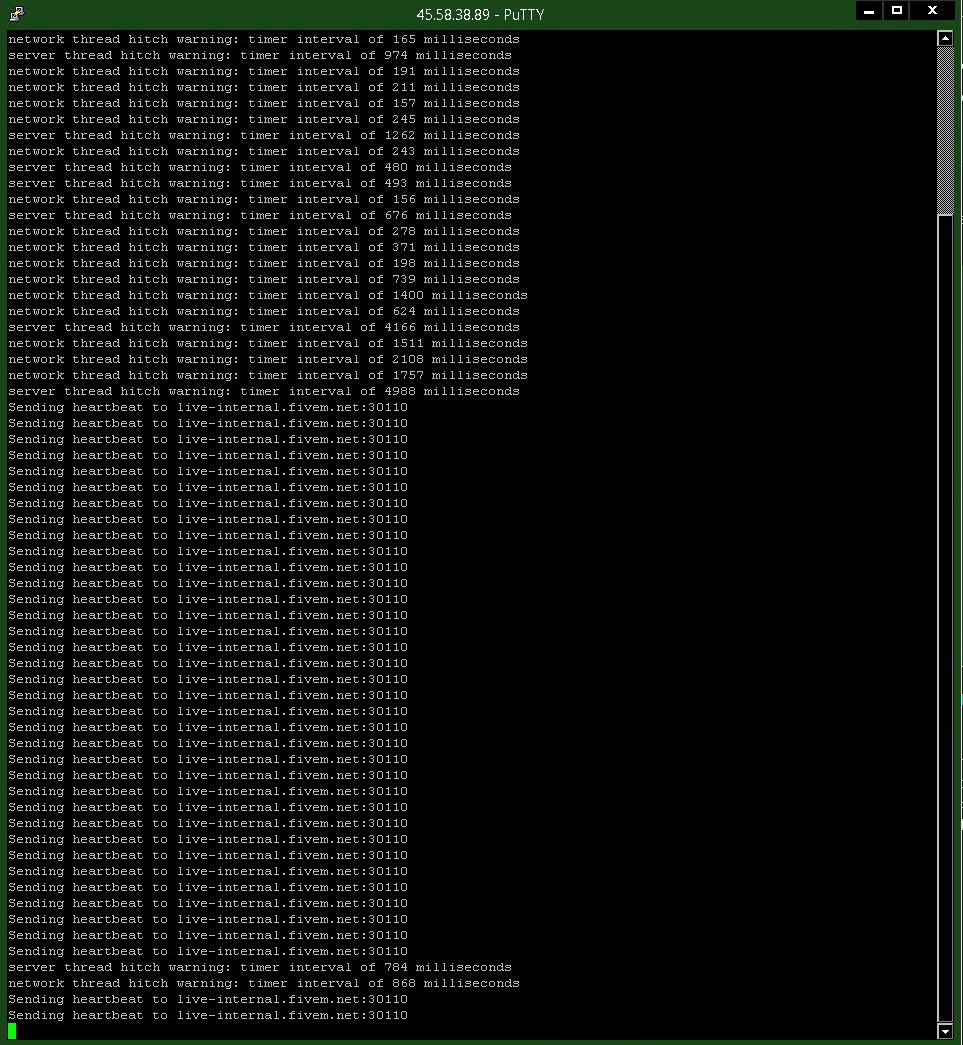
961-1244 hitches and survives, 1317-1347 hitches and crashes every time.
My VPS is a very stock Debian setup, as advised by the great tutorials at Digital Ocean. Usually anything said following the word Linux takes me several hours to understand and implement. There is no fancy configuration here. What ever Debian does stock so does mine.
ok, so your VPS also has very much inconsistent CPU scheduling so it’s definitely not suited for running a game server.
Checking server changes between 1244 and 1313 doesn’t show much that could potentially cause this kind of issue - does it get worse if you e.g. target your server’s port using a HTTP stress test? If so, that’s one potential point that this could’ve changed. 
I have run on three identical VPS for five years: MTA, iv:mp, jc3mp, co-op, fivemp, gta:mp, ■■■■■■■, just to name a few. At my peak I ran on 1 indentical server MTA 20+ players, ■■■■■■ 20+ players, and iv:mp on a single VPS with 4 websites at 500 users a day, and never had a single problem for over 1 year, and that was with docker running ■■■■■■.
I would not know how to do that, but as someone fluent in 14 programming languages I can assure you I have been witnessing this entire process and reporting above all possible conflicts.
Important to remember is that this setup functioned perfectly until 1317 and has displayed the same errors since. my 961 to 1244 servers usually only went down for 1 minute a month when i rebooted the VPS. I have changed nothing since.
I don’t know what this means…
You’re on the 512 MB Digital Ocean plan, right? DO droplets are packed onto hosts and the smaller they are the less priority they have over other VMs on the same host.
So, sometimes you’ll be fine. Other times you’ll have what’s called the “noisy neighbor” effect where another VM on the same host (not controlled by you in any way) comes under load and “steals” CPU from other smaller VMs around it.
Unfortunately, the only real fix is to find a host that “locks” a core to your particular VM which increases the cost. FXServer is sensitive to CPU spikes. Between that and OOM killer the problem appears to be your server and not FiveM.
I can understand that “you’ve had no issues before” and “hosted other game servers”, but you honestly get what you pay for. Pay a bit more to get the resources it actually needs and not attempt to share 512 MB of RAM and a partial CPU core with multiple servers (especially apache). Even if it works for a while, the server is basically a house of cards where any unexpected load spike will cause the whole thing to fall over.
I know it’ll be easier to make this my fault. But you can only do so by ignoring the facts, which you layout in a last response like manner.
I’ve run a dozen mps for the past five years on these exact VPS. Every one of them has been stable or suffering its own internal mod_ded like errors (iv:mp, jc3mp) FiveM linux server, unlike its client, has been an MTA worthy fantasy where all you do is start it and forget it, as it runs for months without concern. FiveM has run without concern for me on this system as long as I can remember, until 1317 arrived. Between 1244 and 1317 FiveM changed something. And after 1317, The FiveM dream became a community destroying nightmare.
If your theories were correct, the past 18 months would have been an equal nightmare of random disconnects, with a sea of problems. Yet to no ones memory have I, who file a lot of tech support issues, ever complained once of random server crashes. The VPS this operates on functions flawlessly on all counts, what is contained in its logs is being misunderstood or misinterpreted, as at no point have I ever witnessed it fail to do anything perfectly.
1349 Crashes. And I hope you know the old customer support saying. For every one person who has the time to complain about something, a 1000 people are suffering from it.
So shall we continue destroying my 10k user a month community, or will you except me to go back to what works?
The logs give nothing about the truth of what’s actually happening in your VPS.
Really, you have a couple choices:
- Upgrade the VPS to a non-budget 512 MB machine so it can actually run everything you have on it.
- Move everything non-fivem related off it so there’s nothing else that could possibly interfere and introduce variables.
- Switch to Windows (which DO doesn’t support) which has historically been more stable and has actual debug tool support.
There are many communities running onesync with zero problems or random crashes. The “crashes” are external shown by the lack of a crash message (it would at LEAST have something other than “Killed”) but we don’t have a magic crystal ball showing the root cause here.
If you want to see for yourself, search for oom-killer in your syslog/messages file. I counted 13 instances in messages. That’s definitely not normal.
I’ve been killed by something. That is for sure. While I pour over the logs. As I contemplate FiveM crashing on an identically prepared second VPS. Do any of the elements want to mention FiveM has become an erratic ram hog, to run One Sync? Are you destroying me, so you can have a little bit more? Because what I am seeing from my testing is that something is suddenly using all the ram available. And there are only two players at work here: FIveM and Apache 2.4. “Something” has suddenly started using huge amounts of ram erratically.
Something suddenly grabs massive amounts of ram. And it sure as hell isn’t Apache. Anyone want to tell me how big a RAM Hog you have made FiveM Server? How much bigger will you make it? You’re killing the little guy so you can have more… My community is decimated by over 50 crashes in 10 days.
My VPS has more than enough memory. More than half of it sits free 99.9% of the time. Until erratically, suddenly, irreversibly it has no memory. So will 1GB fix it? How about 2GB? How about 10GB? It had 3 players on it when it just crashed, and 2 were sitting idle. Where once 25+ would have played for weeks without concern. And it ran out of RAM. Because you guys have some serious flaws in your code, so your OneSync can have more. And everyone else? who cares…
None of the server changes between 1244 and 1313 have had anything to do with cloning.
Look over them yourself. Didn’t you know a lot of programming languages?
Heck, none of them even could have introduced any sort of infinitely growing memory leak, and in fact haven’t for any of the thousands of servers that have updated.
Yes, we’ve been explicitly singling you out since 2016. The entire project exists only to destroy your community, since we hate you so much for no reason at all, that we love to see one person get destroyed time after time.
That’s sarcasm, by the way.
Your logs very clearly stated that there was only 128 MB of RAM free for FXServer at the time of the OOM situations.
At time of OOM kill, Apache has been using ~300 MB of RAM, whereas FXS has been using 128 MB. Also you or your VPS provider somehow disabled swap as your system literally never falls back to swap.
It uses literally the same amount of memory as it always did.
What the fuck does this want to mean? How do we get ‘more’ of an unspecified item just because someone decides to run a game server on a VPS that at its worst has only 128 MB of free memory?
Maybe go and track it using a tool like netdata.
As you could’ve seen in the code diff above, no changes were made relating to OneSync at all. Also - again this ‘have more’? Have more of what?
Thousands of servers, both running 1s and non-1s work fine since the update.
2 Likes
I’ve been here as a spy from gta-mp since 2015…
I agree 
It does not
…more players per server?
So I am currently running my server on a new VPS with 2GB of ram, and nothing else running. It has run for 15 hours without crashing. Typically it never got past 4-8 hours, and usually crashed around 5 hours. It is a stock Debian 9 build exactly as the previous VPS. But unlike the previous which ran stable for two years on 512MB of ram, this has 2GB. It is running nothing else at all. Debian, screen, wget, iftop, and FiveM. I run no database, I have no SQL, and never have. It is just FiveM, just like always.
FiveM on 2GB of ram
free -m
total used free shared buff/cache available
Mem: 1956 134 1033 11 788 1641
Swap: 0 0 0
Which is a lot, even when FX Server was not occasionally grabbing all available RAM. Which is what I saw on the previous system, prior to every crash “something” suddenly grabs everything available. 200MBs of ram causing linux to kill off everything to save itself.
FiveM on 512MB normally…
free -m
total used free shared buff/cache available
Mem: 492 196 221 11 73 271
Swap: 511 0 511
then post 1317, the server would start hitch warning. During which it would gobble up every bit of RAM available while displaying this…
free -m
total used free shared buff/cache available
Mem: 492 459 6 11 26 8
Swap: 511 0 511
And you are just wrong on all counts if you believe that Apache, with no SQL, and less than 250 users a day is responsible for this action. Because FiveM upto 1244 lived under the same situation for years, and never crashed one time. 1317 and beyond crashed five times a day since, across two identical 512MB RAM servers. And now runs without crashing on 2GB of ram.
You’ve built yourself a big, fat, erratic ram hog to allow some users to have more players. And destroyed my community with its crashes. As you all categorically deny this possibility.
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.