This issue has been resolved in DMs
This is incredibly useful. Thanks for releasing it to the public 
However, there must be a way to trace the recording back to the author right? Getting at least the player ID would be perfect, or some other Mumble internal connection ID that can also be retrieved in FiveM scripts?
EDIT: I found out it says the playername/id in the webhook. It would still be cool for it to trigger an event on the server though 
EDIT 2: Another thing I didn’t quite understand is, is this processing everything on the host machine? Because I have 2 servers that are almost always 50/50, and I noticed it records around 50-60MB every minute. The space isn’t really a problem, however the CPU usage goes up to constant 100% (it’s a dedicated Xeon CPU)
EDIT 3: For me, it already crashed 2/3 times, if you need it, I got the traceback 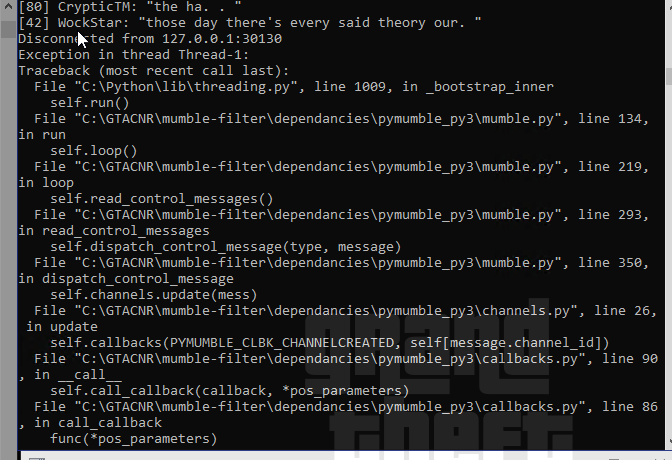
File "C:\Python\lib\threading.py", line 1009, in _bootstrap_inner
self.run()
File "C:\GTACNR\mumble-filter\dependancies\pymumble_py3\mumble.py", line 134, in run
self.loop()
File "C:\GTACNR\mumble-filter\dependancies\pymumble_py3\mumble.py", line 219, in loop
self.read_control_messages()
File "C:\GTACNR\mumble-filter\dependancies\pymumble_py3\mumble.py", line 293, in read_control_messages
self.dispatch_control_message(type, message)
File "C:\GTACNR\mumble-filter\dependancies\pymumble_py3\mumble.py", line 350, in dispatch_control_message
self.channels.update(mess)
File "C:\GTACNR\mumble-filter\dependancies\pymumble_py3\channels.py", line 26, in update
self.callbacks(PYMUMBLE_CLBK_CHANNELCREATED, self[message.channel_id])
File "C:\GTACNR\mumble-filter\dependancies\pymumble_py3\callbacks.py", line 90, in __call__
self.call_callback(callback, *pos_parameters)
File "C:\GTACNR\mumble-filter\dependancies\pymumble_py3\callbacks.py", line 86, in call_callback
func(*pos_parameters)
File "C:\GTACNR\mumble-filter\DalraeMumbleBot.py", line 144, in channelCreated
self.mumble.users.myself.add_listening_channels([channel["channel_id"]])
AttributeError: 'NoneType' object has no attribute 'add_listening_channels'
Process Terminated.
I don’t know anything about Python, is there a way to catch the exception and avoid the program crashing?
Hello,
Yes, currently the only way to trace the recording back to the author is through the file name and the text prepended to the webhook message.
I completely agree! It would be awesome to have some FiveM implementation into the bot. Currently, however, I don’t know how to do that. If someone submits a PR, I will gladly merge it, though!
Yes, all processing is done on the host machine. Transcribing voice is a very intensive process. It is possible, however, to run the bot from any other machine connected to the internet if you don’t want to bot to affect your server’s performance.
Thank you for bringing this error to my attention!
This is due to me not removing the pymumble callbacks when the bot has become disconnected from the server, and it attempts to refer to a mumble instance that doesn’t exist. I have published a fix on Github.
1 Like
Thank you for being so fast! I’m gonna update it now
Meanwhile I had edited the batch file to make it restart every time it crashed 
As for the implementation, I think there’s a way to call server commands from an external remote app, Tebex does that. I just don’t know how.
Tebex has official support by FiveM, so I think that has something to do with it, however I will definitely look into it
Alright, I have added support for Rcon commands! Use this in your resource by doing
RegisterCommand("Dalrae:MumbleBotRecieve", function(_, args, raw)
local array = json.decode(table.concat(args, " "))
print(array.Username)
print(array.Message)
end, true)
which will result in the output
[1] Dalrae
test.
1 Like
Thank you, I’ll try it out today!
Does it also let me get the player server ID?
Well it exclusively connects to the Mumble server (And I don’t think you can get a user’s mumble session ID in FiveM yet), but luckily FiveM provides Mumble with the user’s ID in their username.
The only issue with that is that anyone can connect to the mumble server externally and set their name to look like it has a specific ID when, in fact, they do not.
So currently it’s best practice to not use the ID in the username to any degree until FiveM implements a way to identify a Mumble user with a session ID.
works great, nice release kind mister.
Thank you other kind mister
Finally got a chance to test this out. Quite impressive!
The CPU usage is a bit problematic. Any ways to try to optimize this from eating multiple cores?
Also, I see a lot of false transcriptions. Does this improve over time?
When it comes to Linux, is there a solid way to get this stable? Windows runs perfectly, but on Linux it doesn’t seem to want to stay running for long before crashing/creating issues.
Voice transcriptions are very resource intensive, sadly. You may be able to decrease the CPU usage by using a smaller training model
Sadly there are alot of problems with transcribing speech, but I have no control over how accurate it is. A solution is to use a better/bigger training model
I have only ever tested with with Windows. Could you provide some errors you were experiencing? It’s probably something to do with the file directories
Sorry to just now be getting back to you.
We have actually been doing some tweaks and now we have it successfully running on Linux. Quite glad too, as Windows licenses are going up. In relation to Windows vs Linux, each instance uses about 30% less resources with how we’ve configured it compared to Windows. Definitely a major milestone with this.
We continue to make tweaks as we’ve found making changes to the OPUS configuration not only improves performance, but also improves overall reliability. Now we don’t experience any crashes at all.
That’s great! Would you mind sharing your OPUS configuration findings with the community?
Any chance to support Hungarian language?
Currently, it doesn’t seem like Vosk has any official models for the Hungarian language: VOSK Models
We’re actually running four separate configurations at the moment. Playing around with it as we learn changes and triggers.
Alright, keep us updated! I never messed with the OPUS configuration
So there’s actually a wealth of configuration methods in that.
Turns out by tweaking the bit configuration within the codecs, can lower the CPU demand, while fine tuning and in some cases even improving the detection.
The other issue we’ve found is the bitrates themselves were more variable, which impacted the actual codec recognition. Bands are also an important part of the framesize as a whole.
That’s really interesting! Would you mind sharing your specific configuration? It sounds like it could drastically improve the script, and perhaps even increase the demand for the script. I know a few people that have decided to not use this based on the sole fact that it is extremely inefficient. Actually, that’s one of the main reason I don’t run it on my server!